
Artificial intelligence is evolving rapidly, and multimodal AI stands at the forefront of this technological revolution. By integrating multiple types of data and sensory inputs, multimodal AI systems are pushing the boundaries of what machines can perceive and understand. This groundbreaking approach has an impact on various industries, from healthcare to entertainment, opening up new possibilities for human-machine interaction and problem-solving.
In this article, we’ll explore the top 10 real-world innovations and examples of multimodal AI. We’ll start by explaining what multimodal AI is and how it differs from traditional AI systems. Then, we’ll dive into the most exciting multimodal AI breakthroughs, showcasing their practical applications across different sectors. Finally, we’ll take a look at what the future holds for this game-changing technology and its potential to shape our world.
Understanding Multimodal AI
Definition
Multimodal AI is a cutting-edge subset of artificial intelligence that combines multiple types of data inputs to create more comprehensive and accurate models 1. This innovative approach allows AI systems to process and analyze various forms of information, including text, images, audio, and video, to gain a more holistic understanding of the world around them 2.
Multimodal learning, a key component of multimodal AI, trains machines to augment their learning capacity by processing large amounts of text along with other sensory data types 3. This enables models to discover new patterns and correlations between textual descriptions and their associated visual or auditory elements, ultimately leading to more nuanced and context-aware AI systems.
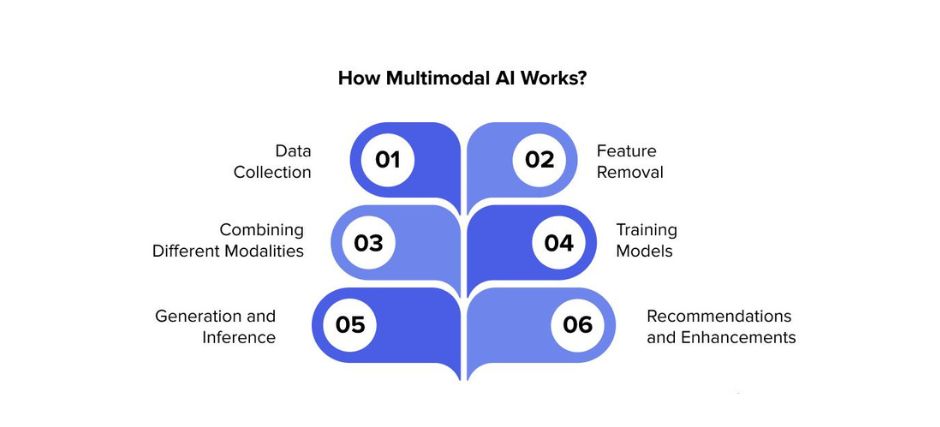
How it Works
Multimodal AI systems typically consist of three main components that work together to process and interpret diverse data types:
- Input Module: This component comprises a series of neural networks responsible for ingesting and processing different types of data. Each data type, such as speech or vision, is usually handled by its own separate neural network .
- Fusion Module: The fusion module combines, aligns, and processes the relevant data from each modality into a cohesive dataset. This step utilizes various mathematical and data processing techniques, including transformer models and graph convolutional networks .
- Output Module: This final component creates the output from the multimodal AI, which may include making predictions, decisions, or recommending actionable insights that the system or a human operator can utilize .
Multimodal AI relies on data fusion techniques to integrate disparate data types and build a more complete and accurate understanding of the underlying information 3. Depending on the processing stage at which fusion takes place, these techniques can be classified into three categories:
- Early fusion: Combining raw data
- Mid fusion: Integrating partially processed data
- Late fusion: Merging fully processed data
The ultimate goal of these fusion techniques is to make better predictions by combining the complementary information that different modalities of data provide .
Comparison with Other AI Types
To better understand the unique capabilities of multimodal AI, it’s essential to compare it with traditional unimodal AI systems:
- Data Scope: Unimodal AI models are designed to analyze and process one type of data, while multimodal AI systems can handle multiple data types simultaneously .
- Contextual Understanding: Multimodal AI excels at understanding context by analyzing multiple data types together, which is crucial for tasks like natural language processing. Unimodal models, on the other hand, are limited in their ability to grasp complex contexts due to their single-data focus .
- Accuracy and Robustness: Multimodal AI systems generally achieve higher accuracy by leveraging information from multiple data types. They are also more robust against noise and variability in input data, improving overall reliability .
- Complexity: Multimodal AI models have more intricate structures composed of multiple modalities and other systems, making them significantly more complex than their unimodal counterparts .
- Application Versatility: Multimodal AI finds applications in diverse fields, enhancing tasks from virtual assistance to healthcare, due to its ability to process and respond to multiple input types .
The advantages of multimodal AI over traditional AI systems include:
- Enhanced accuracy and robustness
- Improved contextual comprehension
- More natural human-machine interactions
- Better interpretability of system outputs
- Reduced errors through cross-referencing data across modalities
By integrating multiple data types and leveraging advanced processing techniques, multimodal AI represents a significant leap forward in artificial intelligence capabilities. Its ability to understand and interpret complex, multi-faceted information opens up new possibilities for AI applications across various industries and domains.
Top 5 Multimodal AI Innovations
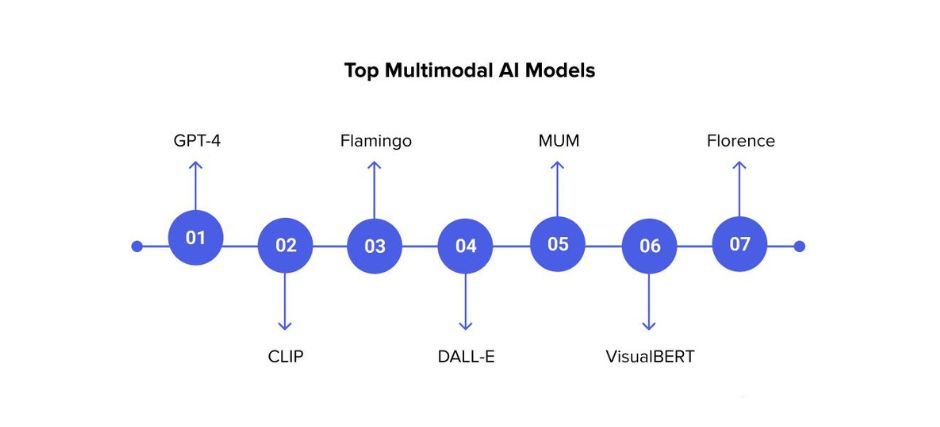
GPT-4
GPT-4, also known as GPT-4 Omni, represents a significant leap forward in multimodal AI technology. This advanced model has the capability to process and analyze various types of data, including text, images, audio, and video . By integrating these different modalities, GPT-4 offers unparalleled flexibility in understanding and interacting with diverse content forms.
One of the key advantages of GPT-4 is its ability to simplify the development process and enhance the functionality of applications. Developers can now create more engaging and responsive user experiences by incorporating GPT-4 into their projects . For instance, a health app could analyze food photos and provide nutritional information, or a customer service bot could understand and respond to both text and voice queries.
GPT-4’s multimodal capabilities also make it more cost-effective and efficient compared to maintaining separate models for each data type. By consolidating data processing needs into a single model, it reduces complexity and lowers the costs associated with training and deploying multiple AI models .
DALL-E
DALL-E is another groundbreaking multimodal AI innovation that has gained significant attention. This model specializes in generating images from textual descriptions, showcasing the power of combining language understanding with visual creativity. DALL-E’s ability to create unique and sometimes surreal images based on text prompts has opened up new possibilities in fields such as graphic design, advertising, and digital art .
CLIP
CLIP (Contrastive Language-Image Pre-training) is a joint image and text embedding model developed by OpenAI. Released in 2021, CLIP has become a fundamental building block for many multimodal AI systems . The model was trained on 400 million image and text pairs in a self-supervised manner, allowing it to map both text and images to the same embedding space .
One of CLIP’s most impressive features is its zero-shot learning capability. Without being explicitly trained on specific datasets, CLIP has achieved remarkable performance on various benchmarks. For example, it matched the accuracy of the original ResNet-50 on the ImageNet dataset, despite not being trained on any of the 1.28 million training examples .
CLIP’s versatility extends to various applications, particularly in semantic search and image retrieval. By embedding both images and text descriptions in the same vector space, CLIP enables efficient search and retrieval of images based on textual queries . This capability has significant implications for improving accessibility in digital content and enhancing user experiences in applications like photo search and recommendations.
MUM
While specific details about MUM (Multitask Unified Model) were not provided in the given factual keypoints, it is worth mentioning as one of the top multimodal AI innovations. MUM, developed by Google, is designed to understand and generate insights across different types of information, including text, images, and video. This model aims to provide more comprehensive and nuanced responses to complex queries by leveraging its multimodal understanding.
Florence
Project Florence, launched by Microsoft Azure Cognitive Services in May 2020, represents a significant advancement in large-scale multitask, multimodal computer vision services . Florence v1.0, a computer vision foundation model, has demonstrated superior performance on challenging tasks such as zero-shot image classification, image/text retrieval, open-set object detection, and visual question answering .
Florence takes a holistic and people-centered approach to learning and understanding by using multimodality. It examines the relationship between three attributes of human cognition: monolingual text (X), audio or visual sensory cues (Y), and multilingual (Z). These attributes are brought together under XYZ-code, a common representation to enable AI that can speak, hear, see, and understand better .
The Florence image captioning model is available to customers through Azure Cognitive Services and is being incorporated into various Microsoft products, including Seeing AI, Word, Outlook, and PowerPoint. This integration helps improve accessibility and enhances user experiences across different platforms . Additionally, the Florence image tagging model is being used in OneDrive to empower photo search and recommendation experiences for millions of users .
These top 5 multimodal AI innovations demonstrate the rapid progress and potential of AI systems that can process and understand multiple types of data simultaneously. As these technologies continue to evolve, they are likely to have a profound impact on various industries and applications, from healthcare and education to entertainment and customer service.
Real-World Applications of Multimodal AI
Multimodal AI has emerged as a transformative force across various industries, revolutionizing the way we approach complex problems and enhancing our ability to process and analyze diverse data types. By integrating information from multiple sources, multimodal AI systems are pushing the boundaries of what’s possible in fields such as healthcare, automotive, finance, retail, and education.
Healthcare
In the healthcare sector, multimodal AI has become an invaluable tool for improving patient care and medical decision-making. By combining data from electronic health records (EHRs), medical imaging, and patient notes, these systems enhance diagnosis, treatment strategies, and personalized care . This integration allows for the identification of patterns and correlations that might be overlooked when analyzing each data type separately, resulting in more accurate diagnoses and customized treatment plans .
One notable example is IBM Watson Health, which integrates data from EHRs, medical imaging, and clinical notes to enable accurate disease diagnosis, predict patient outcomes, and aid in creating personalized treatment plans . Another innovative application is DiabeticU, a diabetes management app developed by Appinventiv, which empowers users to take charge of their health journey by integrating features such as tailored meal plans, medication tracking, and blood sugar monitoring with wearable devices .
In oncology, multimodal AI has shown particular promise. By correlating data from pathology reports, radiology images, and patient symptoms, these systems can detect and stage cancer more accurately . This integrated approach has the potential to lead to earlier diagnoses and improved patient outcomes across various medical specialties.
Automotive
The automotive industry has embraced multimodal AI to enhance vehicle safety, autonomy, and user experience. Self-driving technologies rely heavily on the fusion of data from multiple sensors, including cameras, radar, LIDAR, and ultrasonic sensors. This sensor fusion creates a detailed and dynamic 360-degree view of the vehicle’s surroundings, enabling autonomous vehicles to navigate complex environments safely.
AI-powered sensor integration processes this multi-sensor data in real-time, offering a comprehensive view of the vehicle’s environment. This refined data synthesis allows for precise identification of obstacles, enhancing road safety. Decision-making algorithms assess sensor inputs and contextual data to make instantaneous navigation decisions, enabling vehicles to navigate complex traffic situations autonomously.
Moreover, multimodal AI has applications beyond autonomous driving. It has transformed after-sales service into a proactive, data-driven model. AI-driven analytics anticipate maintenance schedules and customer needs, ensuring high vehicle availability and satisfaction . Additionally, AI-powered systems offer instant, round-the-clock assistance, revolutionizing customer service in the automotive sector.
Finance
In the financial sector, multimodal AI has catalyzed profound transformations, predicting a new era of efficiency, customer satisfaction, and security. By merging diverse data types, such as transaction logs, user activity patterns, and historical financial records, multimodal AI enhances risk management and fraud detection . This integration allows for a more thorough analysis, helping to identify unusual patterns and potential threats more effectively .
J.P. Morgan’s COIN platform exemplifies the power of AI in finance. Using machine learning to interpret commercial loan agreements, it has reduced a process that previously consumed 360,000 hours of work yearly by lawyers and loan officers to mere seconds . Another innovative application is JP Morgan’s DocLLM, which combines textual data, metadata, and contextual information from financial documents to improve the accuracy and efficiency of document analysis .
The synergy between generative AI and conventional AI technologies promises to revolutionize banking and finance further, combining analytical precision with innovative foresight. For instance, while AI automates loan processing based on historical data, generative AI can forecast evolving market conditions, influencing an applicant’s financial stability.
Retail
In the retail sector, multimodal AI is transforming the shopping experience by integrating audio and visual data analysis. Smart mirrors in stores can suggest clothing items by analyzing customers’ verbal requests and physical characteristics . Online, AI-driven recommendation systems enhance the shopping experience by analyzing customer reviews and product images to provide more accurate and personalized product suggestions .
Amazon’s “Just Walk Out” shopping technology exemplifies the power of multimodal AI in retail. This system allows customers to take items from shelves and walk out of the store without going through a traditional checkout process. The AI automatically detects what products are taken or returned to the shelves and charges the customer’s Amazon account accordingly .
Education
In the education sector, multimodal AI is revolutionizing learning experiences by integrating data from multiple sources, including text, video, and interactive content . This integration enhances personalized learning by customizing instructional materials to match each student’s needs and learning preferences .
Duolingo serves as an excellent example of multimodal AI in education. The language-learning platform uses AI to produce interactive, individualized language courses that adapt based on the learner’s ability level and progress. By fusing text, audio, and visual elements, Duolingo creates a more engaging and effective learning experience .
As multimodal AI continues to evolve, its applications across these industries are likely to expand, driving innovation, improving efficiency, and enhancing user experiences in ways we are only beginning to imagine.
The Future of Multimodal AI
Multimodal AI is causing a revolution in various industries, showcasing its potential to tackle complex challenges and enhance our understanding of diverse data types. By merging information from multiple sources, these systems are pushing the boundaries of what’s possible in healthcare, automotive, finance, retail, and education. This blend of different data types has an influence on everything from improving patient care and boosting vehicle safety to enhancing financial risk management and personalizing learning experiences.
As this technology keeps evolving, we can expect to see even more groundbreaking applications in the future. The ability to process and analyze multiple types of data simultaneously opens up new possibilities to solve problems and create innovative solutions. While there’s still much to explore in this field, it’s clear that multimodal AI has a crucial role to play in shaping our technological landscape and improving our daily lives.
FAQs
What is an example of multimodal AI in action?
Multimodal AI can be utilized in various ways, such as enhancing the capabilities of autonomous vehicles by integrating data from multiple sensors like cameras, radar, and lidar. Additionally, it is used in healthcare to develop advanced diagnostic tools by analyzing a combination of images from medical scans, patient health records, and genetic testing.
Which multimodal AI model is considered the best?
Runway Gen-2 is highly regarded as a top multimodal AI model, particularly for its proficiency in video generation. It allows users to input text, images, or videos, and excels in generating original video content with features like text-to-video, image-to-video, and video-to-video functionalities.
What are ten current applications of artificial intelligence?
Artificial intelligence today is applied in several fields including:
- Finance
- Education
- Content creation
- Healthcare
- Retail
- Transportation
- Chatbots and virtual assistants
- Facial recognition
What are two prevalent applications of multimodal generative AI?
Multimodal generative AI is commonly used in:
- Computer Vision: This extends beyond simple object identification to more complex applications.
- Industry: There are numerous workplace applications for multimodal AI.
- Natural Language Processing (NLP): It includes tasks like sentiment analysis.
- Robotics: Multimodal AI plays a significant role in enhancing robotic functionalities.


